spring boot
侧边栏显示隐藏
vulnhub
lamda表达式
最短路
Terminal
终端
程序员
相机参数
镜像复制
TableSQL
redis安装
风控数据分析师
django-redis
heartbeating
分布式框架
CalBioreagents
go入门教程
思考
BCG
ViT
2024/4/13 1:36:26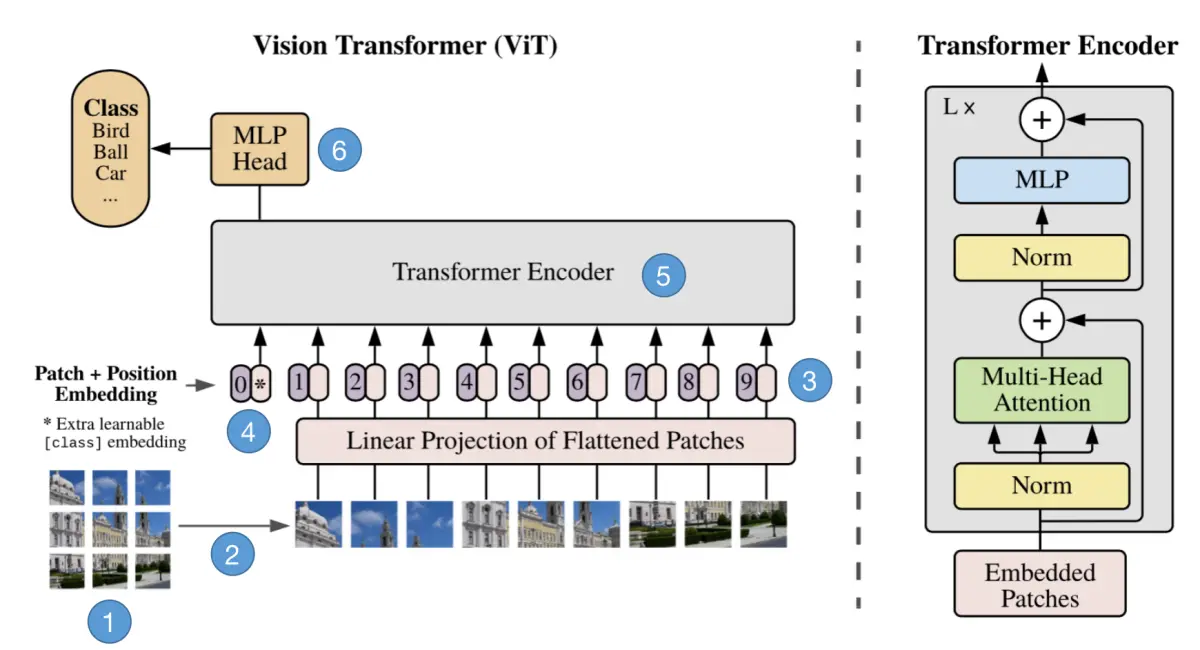
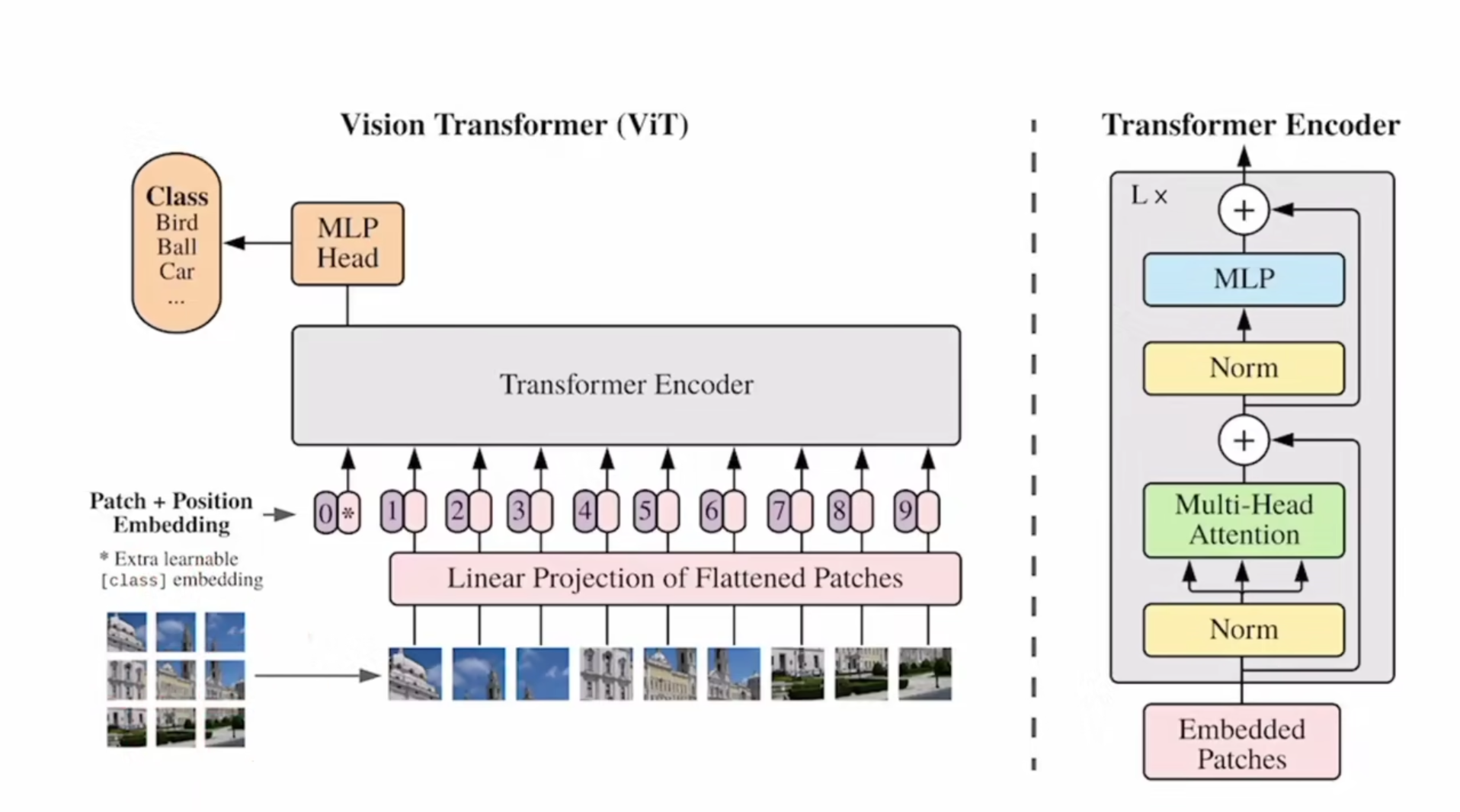
【计算机视觉】Visual Transformer (ViT)模型结构以及原理解析
文章目录 一、简介二、Vision Transformer如何工作三、ViT模型架构四、ViT工作原理解析4.1 步骤1:将图片转换成patches序列4.2 步骤2:将patches铺平4.3 步骤3:添加Position embedding4.4 步骤4:添加class token4.5 步骤5ÿ…
深度学习论文系列--模型细节(持续更新)
AlexNet
图像增强reLu函数Dropout防止过拟合
论文主要思想
更深的卷积神经网络end-to end,端到端的意思就是我只需要把原始的数据(图片、文本等)放进去,不需要做任何的特征提取
ResNet
神经网络深度很深的时候,就…

【计算机视觉】CVPR 23 | 视觉 Transformer 全新学习范式!用长尾数据提升ViT性能
文章目录 一、导读二、介绍三、方法四、总结 一、导读
论文地址:
https://arxiv.org/abs/2212.02015代码链接:
https://github.com/XuZhengzhuo/LiVT二、介绍
在机器学习领域中,学习不平衡的标注数据一直是一个常见而具有挑战性的任务。近…
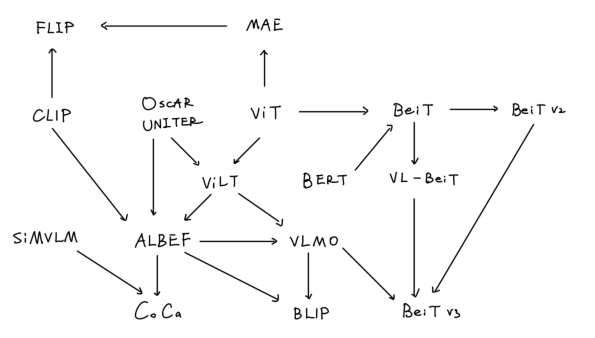
【学习笔记】多模态综述
多模态综述 前言1. CLIP & ViLT2. ALBEF3. VLMO4. BLIP5. CoCa6. BeiTv3总结参考链接 前言
本篇学习笔记虽然是多模态综述,本质上是对ViLT后多模态模型的总结,时间线为2021年至2022年,在这两年,多模态领域的模型也是卷的飞起…

『论文精读』Data-efficient image Transformers(DeiT)论文解读
『论文精读』Data-efficient image Transformers(DeiT)论文解读 文章目录 一. DeiT简介二. 知识蒸馏(knowledge distillation)2.1. KLDivloss2.2. 蒸馏温度 τ \tau τ2.3. distillation in transformer 三. better hyperparameter四. data augmentation五. label smoothing参…

TinyViT: 一种高效的蒸馏方法
目录 背景方法大意快速预训练蒸馏(Fast Pretraining Distillation, FPD)如何实现快速三个细节深入理解FPD 模型架构训练trick预训练参数配置(Imagenet21k-pretraining)finetuning 参数配置(Imagenet-1k) 消融实验**Q: 数据是否越多…

Pytorch从零开始实现Vision Transformer (from scratch)
Pytorch从零开始实现Vision Transformer 前言一、Vision Transformer架构介绍1. Patch Embedding2. Multi-Head Attention3. Transformer BlockFeed Forward 二、预备知识1. Einsum2. Einops 三、Vision Transformer代码实现0. 导入库1. Patch Embedding2. Residual & Norm…
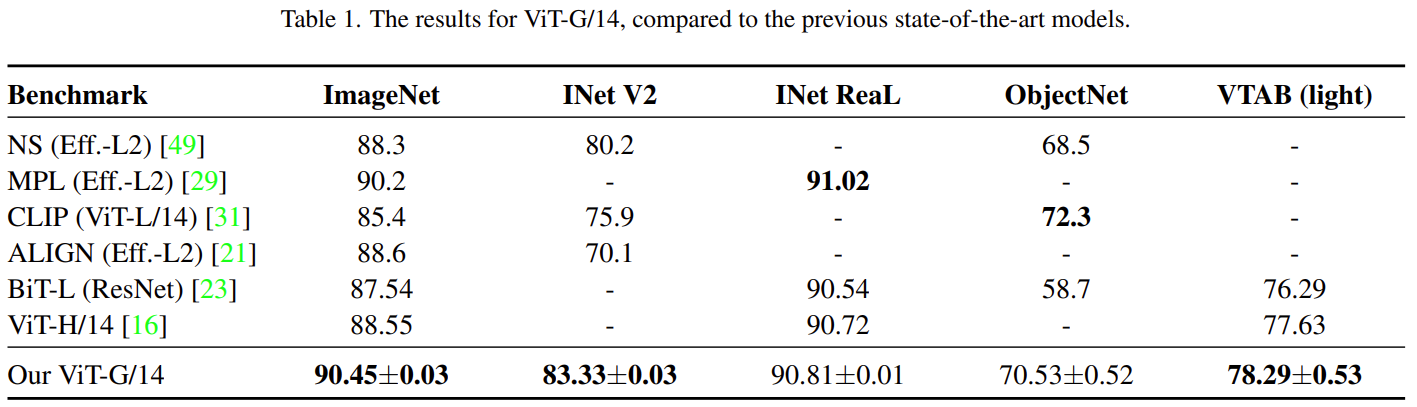
【计算机视觉 | ViT-G】谷歌大脑提出 ViT-G:缩放视觉 Transformer,高达 90.45% 准确率
文章目录 一、简介二、如何做到的?三、扩展数据四、「head」 的解耦权重衰减五、通过移除 [class] token 节省内存六、实验结果6.1 将计算、模型和数据一起扩展6.2 ViT-G/14 结果 论文地址为: https://arxiv.org/pdf/2106.04560.pdf一、简介
视觉 Trans…
AI绘画能力的起源:通俗理解VAE、扩散模型DDPM、DETR、ViT/Swin transformer
前言
2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如
2014 R-CNN2015 Fast R-CNN、Faster R-CNN2016 YOLO、SSD2…
图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer
前言
2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如
2014 R-CNN2015 Fast R-CNN、Faster R-CNN2016 YOLO、SSD2…

EfficientFormer:高效低延迟的Vision Transformers
我们都知道Transformers相对于CNN的架构效率并不高,这导致在一些边缘设备进行推理时延迟会很高,所以这次介绍的论文EfficientFormer号称在准确率不降低的同时可以达到MobileNet的推理速度。 Transformers能否在获得高性能的同时,跑得和Mobile…

【论文笔记】Attention和Visual Transformer
Attention和Visual Transformer Attention和Transformer为什么需要AttentionAttention机制Multi-head AttentionSelf Multi-head Attention,SMA TransformerVisual Transformer,ViT Attention和Transformer
Attention机制在相当早的时间就已经被提出了&…
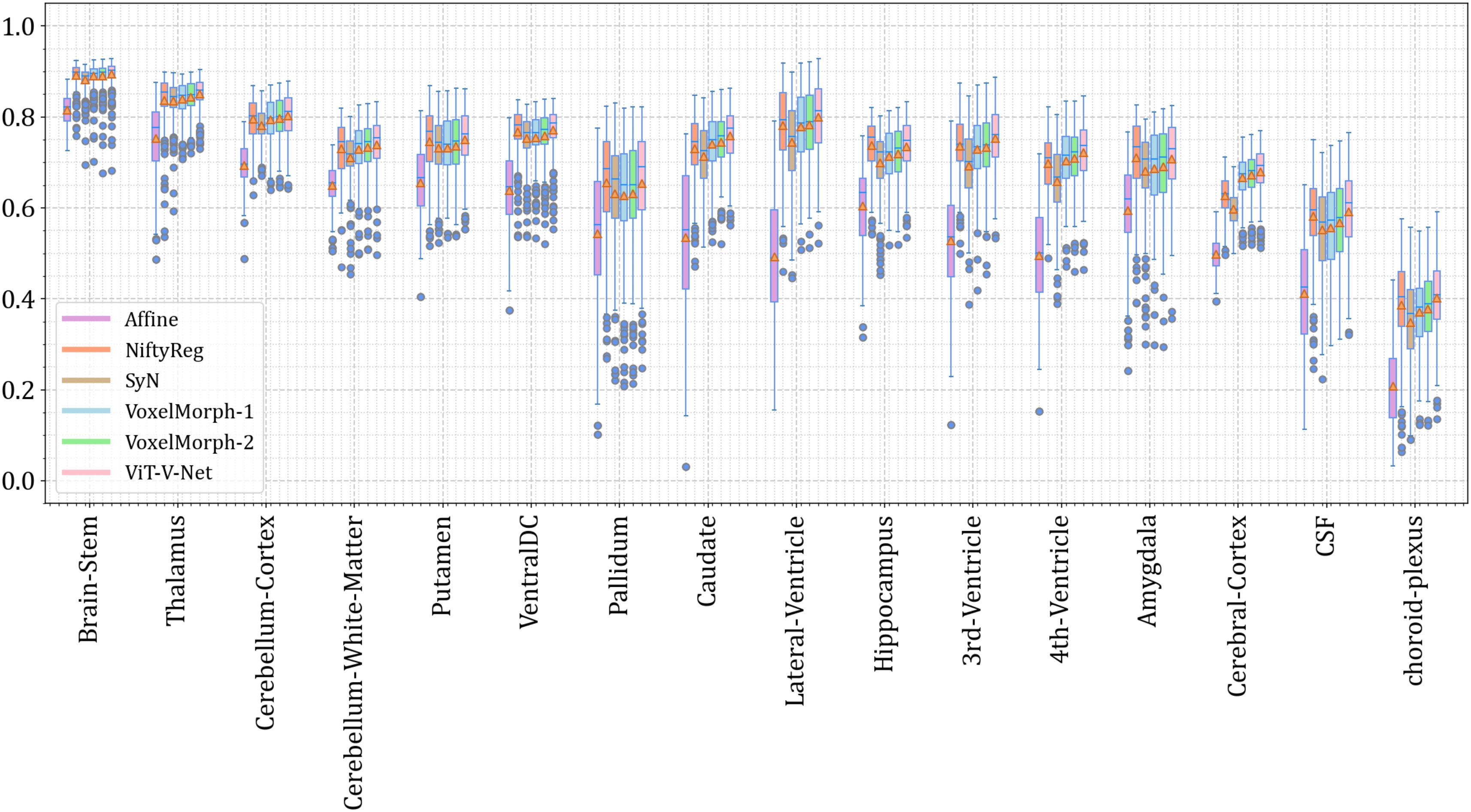
3D医疗图像配准 | 基于Vision-Transformer+Pytorch实现的3D医疗图像配准算法
项目应用场景 面向医疗图像配准场景,项目采用 Pytorch ViT 来实现,形态为 3D 医疗图像的配准。
项目效果 项目细节 > 具体参见项目 README.md (1) 模型架构 (2) Vision Transformer 架构 (3) 量化结果分析 项目获取 https://download.csdn.net/down…

CV计算机视觉每日开源代码Paper with code速览-2023.11.1
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】Battle of the Backbones: A Large-Scal…

SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
摘要
在本文中,我们提出了一种新的序列到序列学习框架的视觉跟踪,称为SeqTrack。它将视觉跟踪转换为一个序列生成问题,它以自回归的方式预测对象边界盒。这与之前的Siamese跟踪器和transformer跟踪器不同,它们依赖于设计复杂的磁…

【Transformer系列】深入浅出理解ViT(Vision Transformer)网络模型
一、参考资料
极智AI | 详解 ViT 算法实现 MobileViT模型简介 ECCV 2022丨力压苹果MobileViT,这个轻量级视觉模型新架构火了 ECCV 2022丨轻量级模型架构火了,力压苹果MobileViT(附代码和论文下载) 再读VIT,还有多少细…

【跟着代码读论文】ViT(2021 ICLR)An image is worth 16x16 words: Transformers for image recognition at scale
论文: An image is worth 16x16 words: Transformers for image recognition at scale.
Github code(PyTorch Implementation):https://github.com/lucidrains/vit-pytorch 目录
Model Overview
Github Code Usage
Procedure …
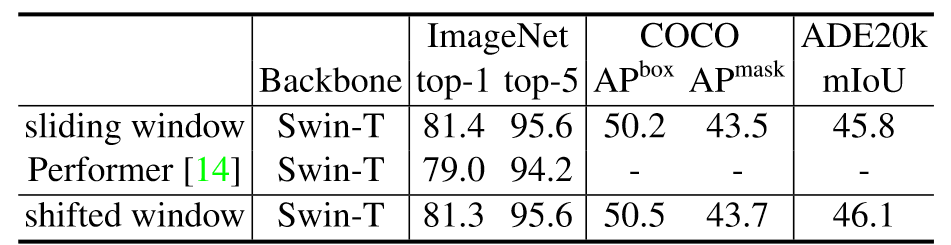
【论文精读】Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 前言Abstract1. Introduction2. Related Work3. Method3.1. Overall Architecture3.2. Shifted Window based Self-AttentionSelf-attention in non-overlapped windowsShifted window partitioning …
图像分类任务ViT与CNN谁更胜一筹?DeepMind用实验证明
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
今天跟大家分享DeepMind发表的一篇技术报告,通过实验得出,CNN与ViT的架构之间虽然存在差异,但同等计算资源的预…

ViT细节与代码解读
最近看到两篇解读ViT很好的文章,备忘记录一下:
先理解细节
1:再读VIT,还有多少细节是你不知道的
再理解代码
1:ViT源码阅读-PyTorch - 知乎
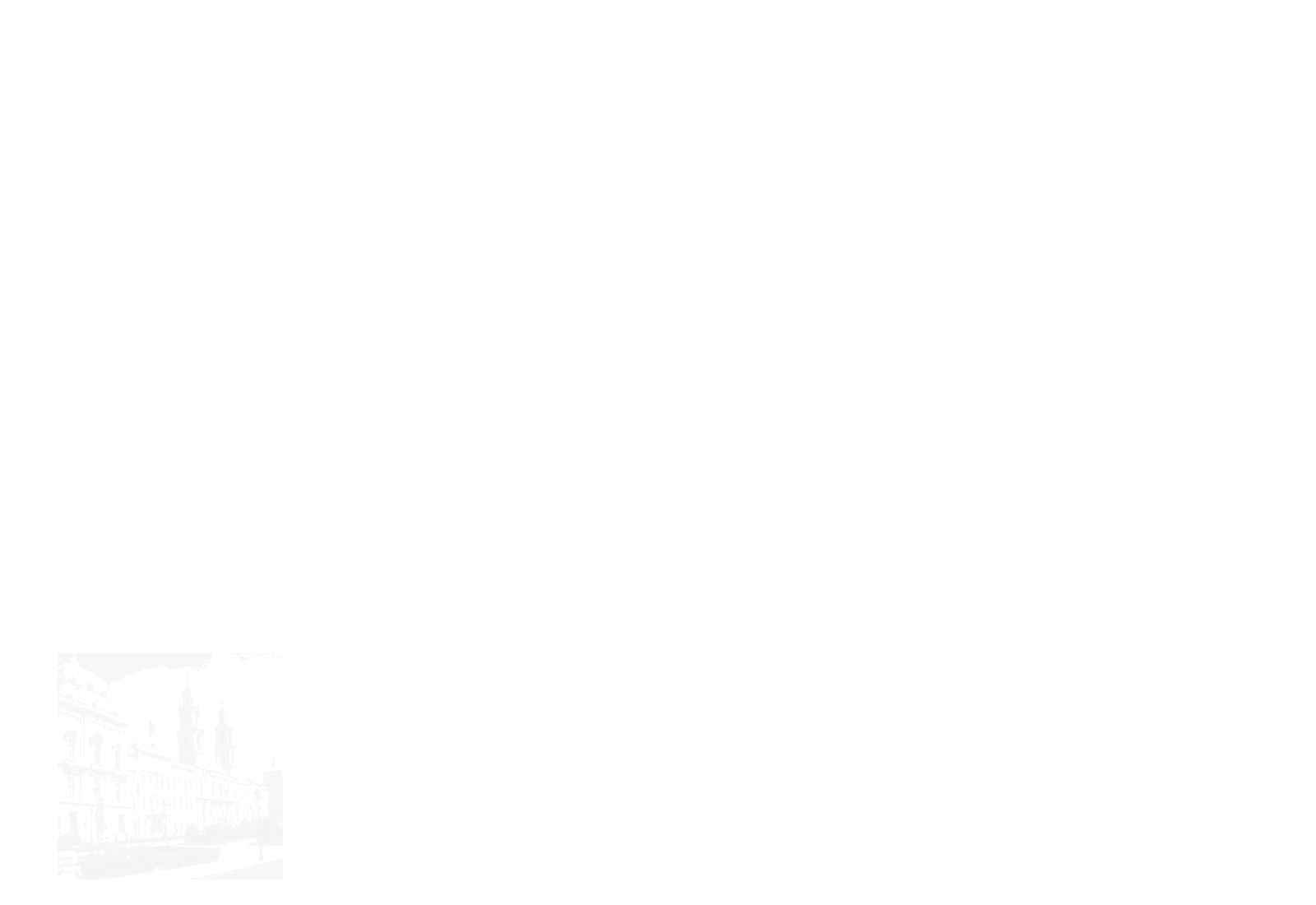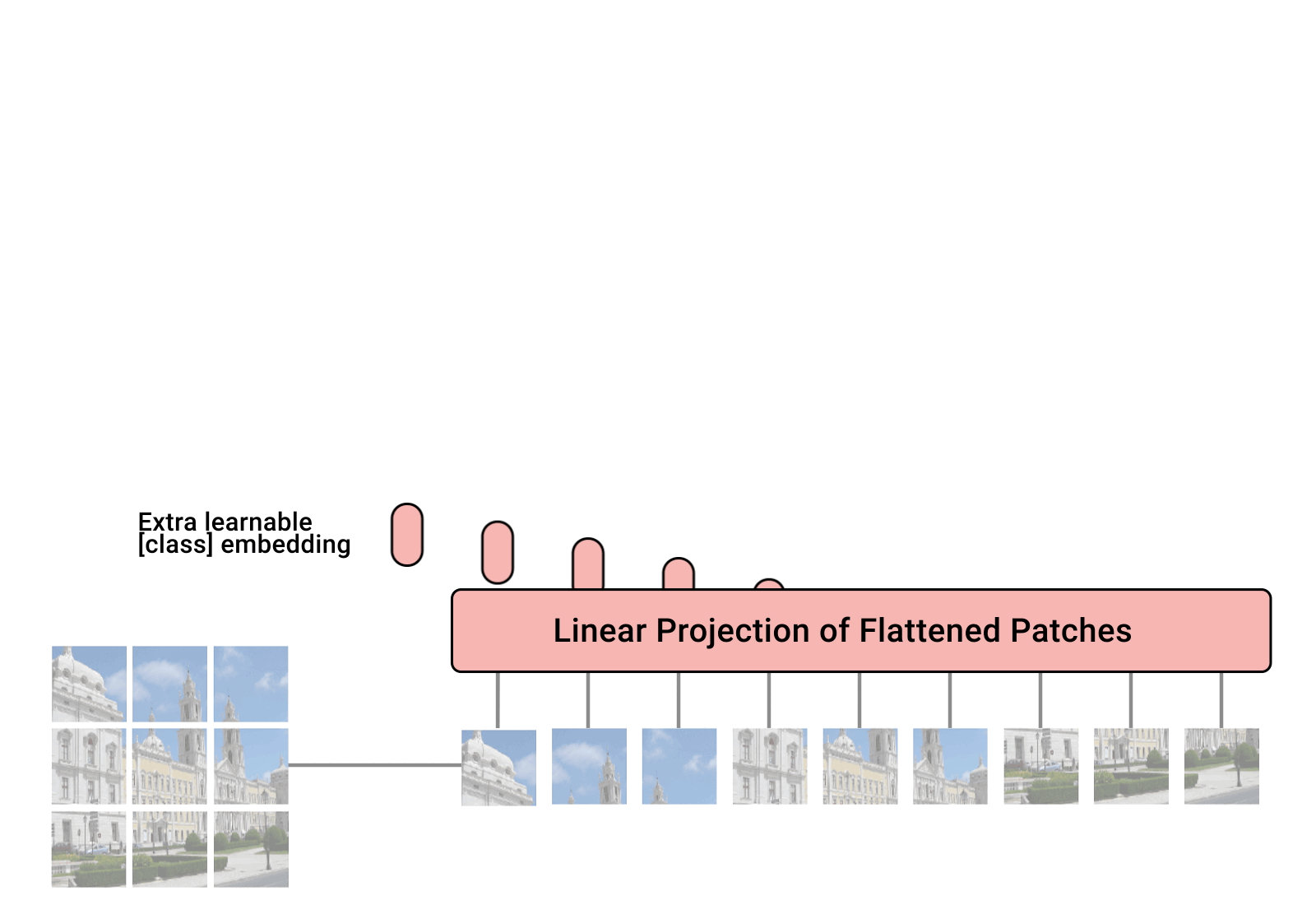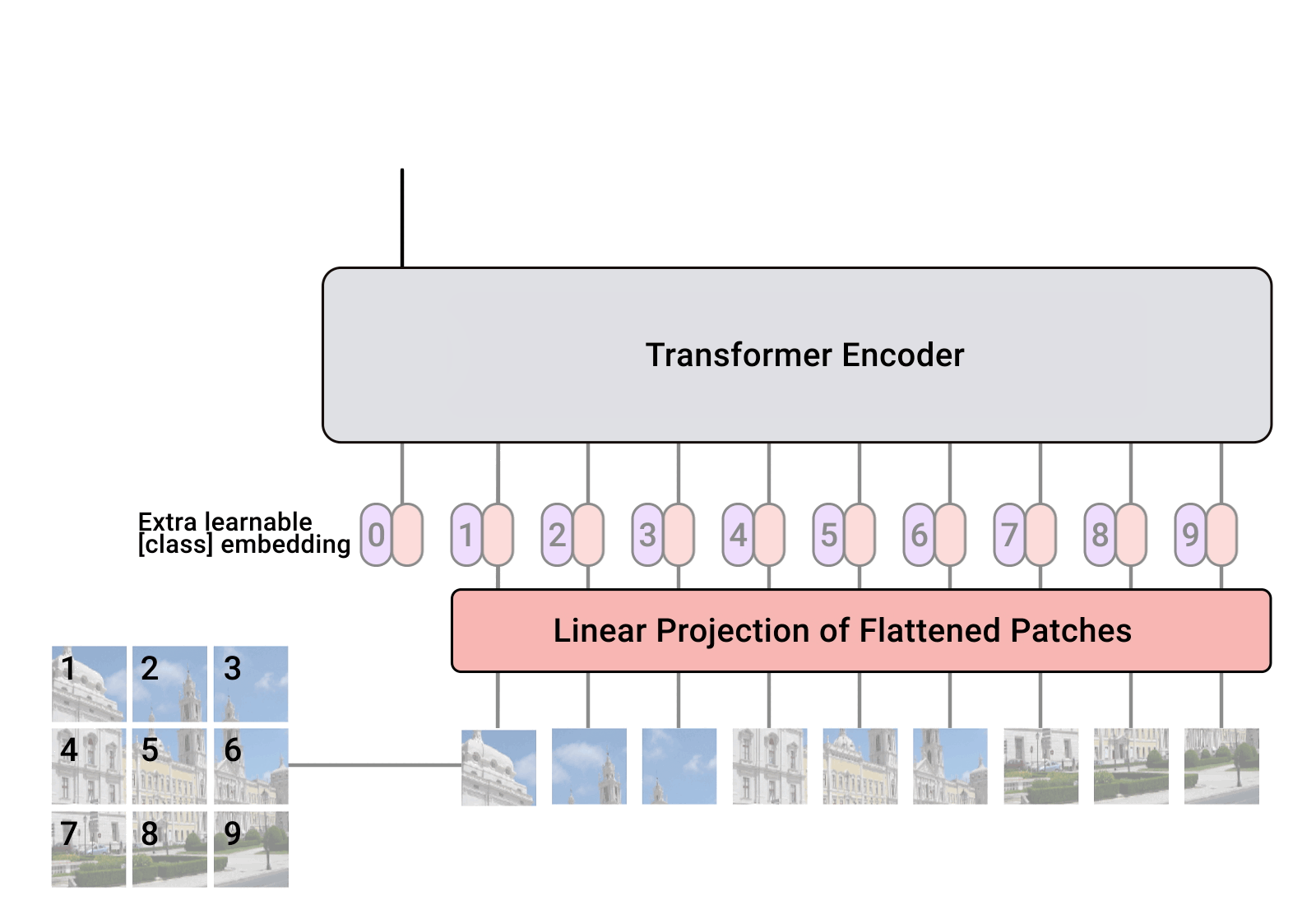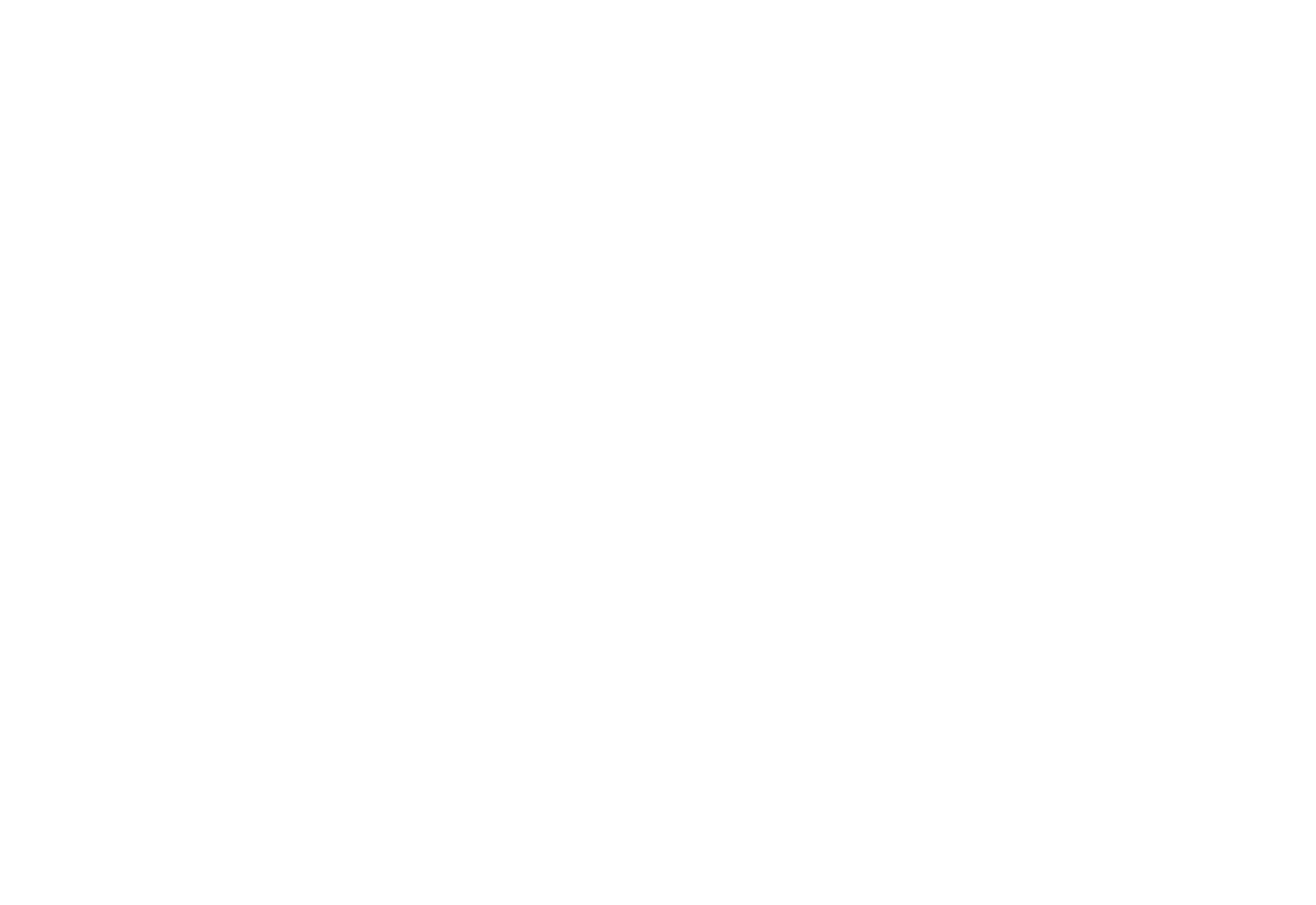
机器学习笔记 - 在 Vision Transformer 中可视化注意力
2022 年,视觉变换器(ViT) 成为卷积神经网络(CNN) 的有力竞争对手,后者现已成为计算机视觉领域的最先进技术,并广泛应用于许多图像识别应用中。在计算效率和准确性方面,ViT 模型超过了当前最先进的 (CNN) 几乎四倍。
一、视觉转换器 (ViT) 如何工作? 视觉转换器模型的性能…